S-JEPA: A Joint Embedding Predictive Architecture for Skeletal Action Recognition
Mohamed Abdelfattah
Alexandre Alahi
École Polytechnique Fédérale de Lausanne (EPFL)
firstname.lastname@epfl.ch
Abstract
Masked self-reconstruction of joints has been shown to be a promising pretext task for self-supervised skeletal action recognition. However, this task focuses on predicting isolated, potentially noisy, joint coordinates, which results in inefficient utilization of the model capacity. In this paper, we introduce S-JEPA, Skeleton Joint Embedding Predictive Architecture, which uses a novel pretext task: Given a partial skeleton sequence, predict the latent representations of the missing joints of the same sequence. Such representations serve as abstract prediction targets that direct the modelling power towards learning the high-level context and depth information, instead of unnecessary low-level details. To tackle the potential non-uniformity in these representations, we propose a simple centering operation that is found to benefit training stability, effectively leading to strong off-the-shelf action representations. Extensive experiments show that S-JEPA, combined with the vanilla transformer, outperforms previous state-of-the-art results on NTU60, NTU120, and PKU-MMD datasets.
Framework
Overview of S-JEPA. First, diverse skeleton views are obtained by applying geometric transformations on the 3D skeletons. The view skeletons are passed through the view encoder, after which learnable mask tokens are inserted at the locations of masked joints to get the view features. The predictor takes the view features as input and outputs the predicted representations $\mathbf{R}_p$ of the missing joints at the locations of the mask tokens. The target representations $\mathbf{R}_t$ are obtained by the target encoder, which takes unmasked 3D skeletons as input, and is updated through the Exponential Moving Average (EMA) of the view encoder weights after each iteration (sg denotes stop gradient). The centering and softmax operations aid in stabilizing the training loss. At fine-tuning and test times, only the target encoder weights are used.
Results
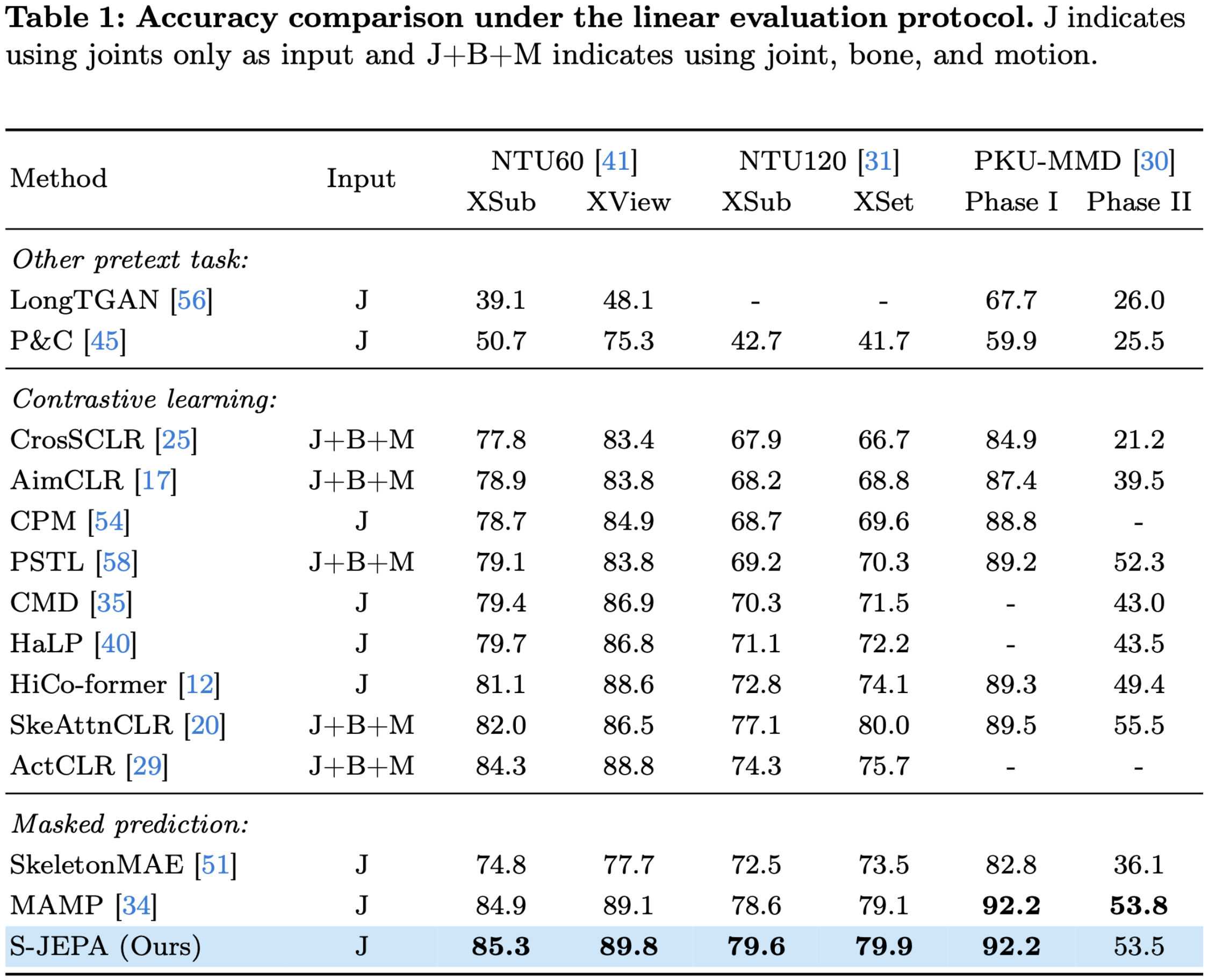
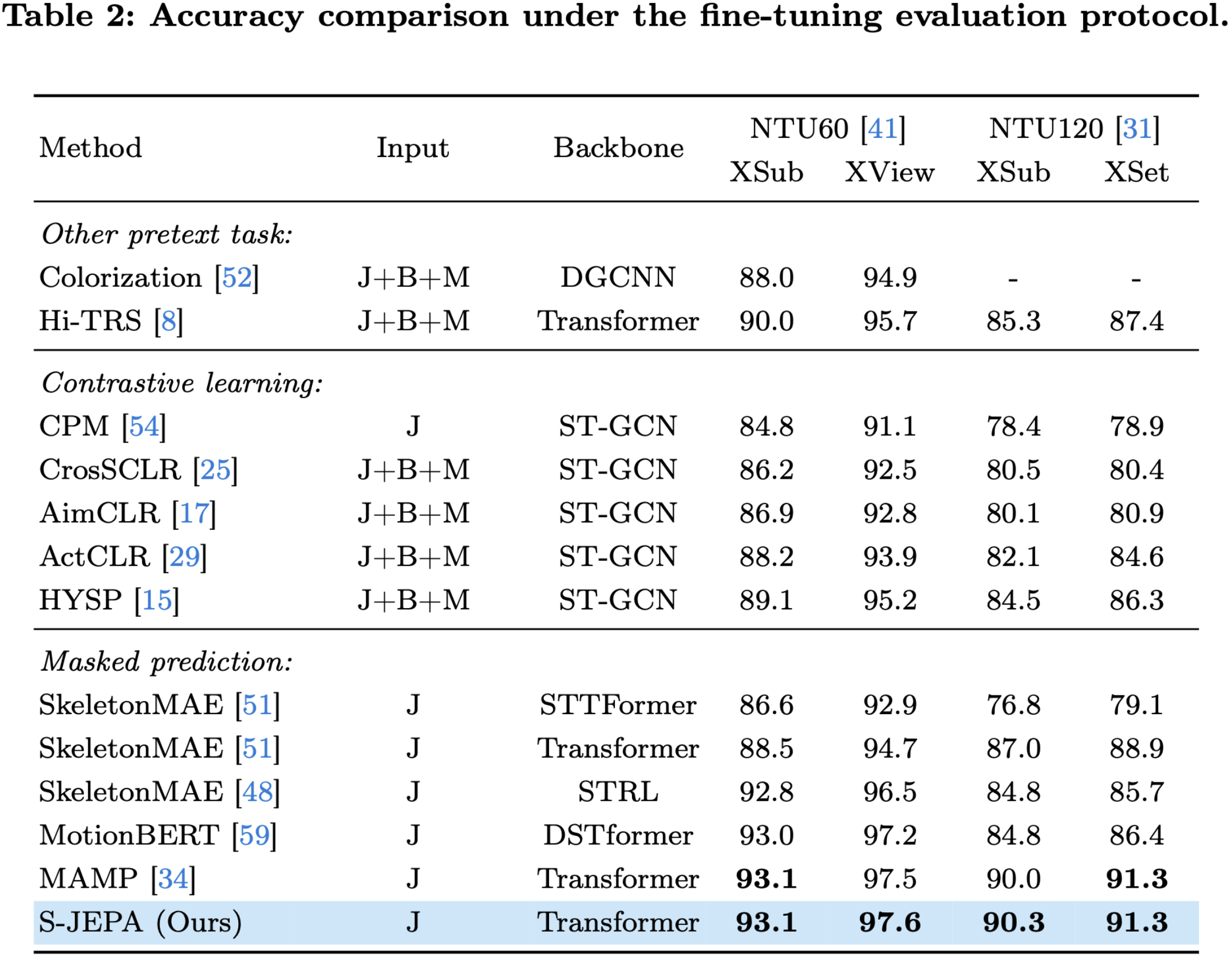
Citation
@inproceedings{abdelfattah2024sjepa, author={Abdelfattah, Mohamed and Alahi, Alexandre}, booktitle={European Conference on Computer Vision (ECCV)}, title={S-JEPA: A Joint Embedding Predictive Architecture for Skeletal Action Recognition}, year={2024}, organization={Springer}, }
Reference
[1]. Mao, Y., Deng, J., Zhou, W., Fang, Y., Ouyang, W., & Li, H. (2023). Masked motion predictors are strong 3d action representation learners. In Proceedings of CVPR.
[2]. Yan, H., Liu, Y., Wei, Y., Li, Z., Li, G., & Lin, L. (2023). Skeletonmae: graph-based masked autoencoder for skeleton sequence pre-training. In Proceedings of ICCV.
[3]. Shahroudy Amir, Jun Liu, Tian-Tsong Ng, and Gang Wang. "Ntu rgb+ d: A large scale dataset for 3d human activity analysis." In Proceedings of the IEEE conference on computer vision and pattern recognition, 2016.